The status quo
Back in November 2023,
the parallel front-end of the Rust compiler was announced.
This means that one could achieve faster compilation by exploiting the now multi-threaded front-end.
In practice, users would exploit this feature with something resembling RUSTFLAGS='-Zthreads=0' cargo build1.
In a typical Cargo build, multiple rustc processes concurrently churn crates into build artifacts.
These processes coordinate through GNU Make Jobserver
to ensure their combined thread count doesn't exceed a set value.
In rustc's front-end, assuming an invocation with -Zthreads=T,
a worker pool of T threads is created.
Each worker thread
acquires
a token from the Jobserver before doing work and releases the token upon completion.
If no token is available, then work simply awaits (in a work-stealing queue) the next available worker.
The rustc
backend-end works differently.
Assuming the LLVM codegen backend is used, all code generation units (CGUs) are transformed into LLVM modules
before being optimized in a dedicated thread.
Again, the Jobsever is used to ensure that the number of LLVM optimization threads never increases beyond a set value.
Room for improvement?
If CPU usage is always at maximum during a Cargo build with -Zthreads=1,
and crates don't spend significant time in the compiler front-end,
then increasing the front-end thread pool size beyond 1 is unnecessary.
Indeed, build times might degrade due to inefficient resource utilization.
Heuristically, we should set -Zthreads=N with N > 1 only for crates that spend
a long duration in the front-end and whose compilation coincides with low CPU
usage. N should not exceed the available CPU cores on the system, nor increase
beyond the point where benefits from parallelism plateau.
A prototype implementation that sets rustc flags on a crate-by-crate basis is
available in this rust-lang/cargo branch.
For example, setting CARGO_CRATE_cargo_RUSTFLAGS='-Zthreads=8' will pass -Zthreads=8
specifically to the rustc invocation compiling the cargo crate.
Results
I ran experiments to see whether setting -Zthreads on a crate-by-crate basis
can lead to faster compilation of a Cargo package. For this I compiled Cargo
886d5e4
on a MacBook Air M1 with 16GB of RAM running macOS 14.2.1 and Rust
1.87.0-nightly (85abb2763 2025-02-25) with the following build configurations:
RUSTFLAGS='-Zthreads=1'RUSTFLAGS='-Zthreads=0'CARGO_CRATE_cargo_RUSTFLAGS='-Zthreads=0'CARGO_PROFILE_DEV_CODEGEN_BACKEND=craneliftCARGO_PROFILE_DEV_CODEGEN_BACKEND=cranelift RUSTFLAGS='-Zthreads=0'CARGO_PROFILE_DEV_CODEGEN_BACKEND=cranelift CARGO_CRATE_cargo_RUSTFLAGS='-Zthreads=0'
Below is a plot of the time spent in rustc's front-end and back-end for crates
that show significant compile time improvements or regressions and for each of
the above configurations2:
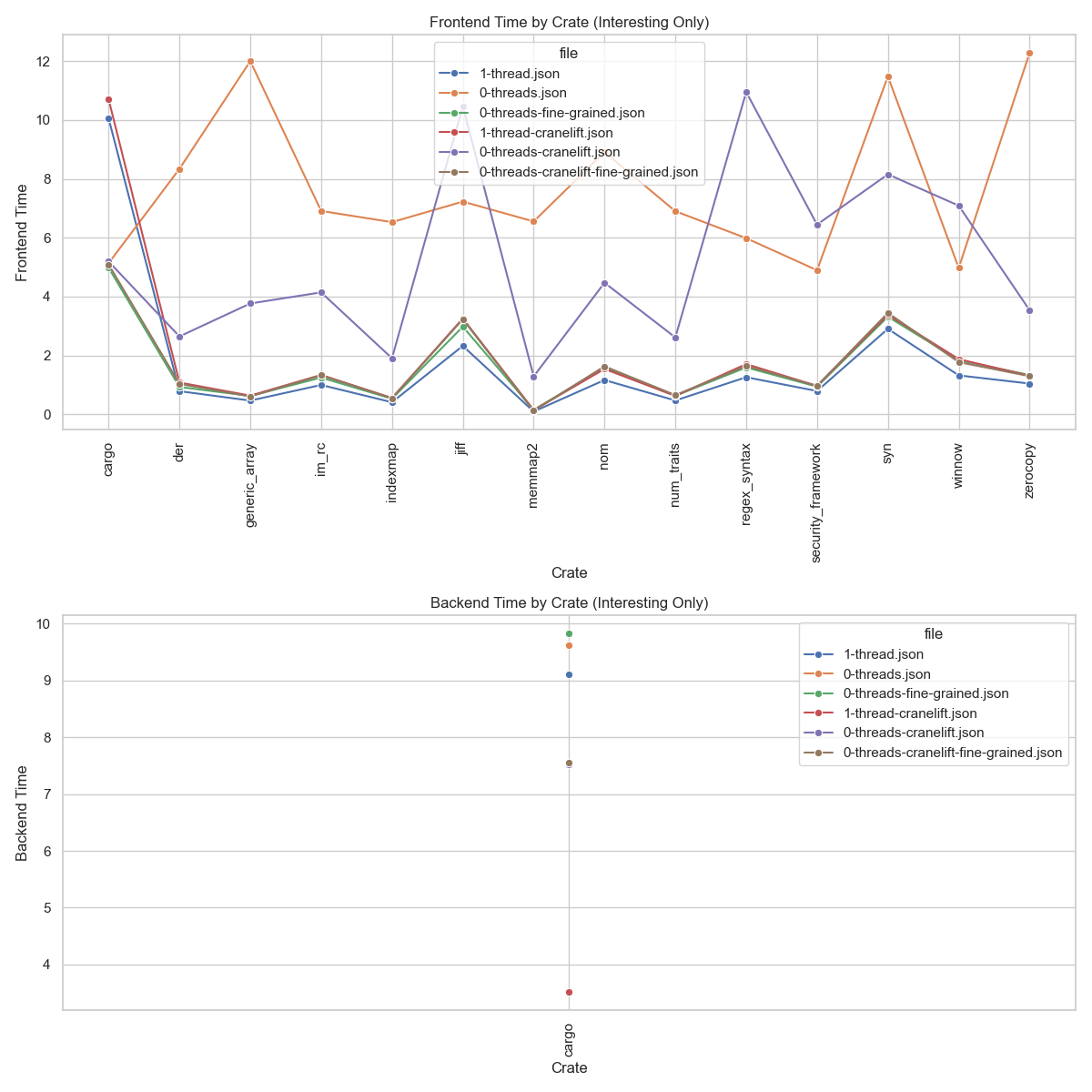
CARGO_CRATE_cargo_RUSTFLAGS='-Zthreads=0'Fine-grained parallelism in rustc's front-end provides compile-time
improvements for "front-end-bound" crates while avoiding regressions in the
remainder of the dependency graph.
A more efficient codegen backend might further free CPU resources, potentially unlocking even greater benefits from front-end parallelism.
Passing -Zthreads=0 means using as many threads as there are CPUs on the
system (i.e. "the num_cpus behavior").
Source code can be found here.